
You have developed an innovative product and want to ‘conquer’ the markets. Your product is complex and is composed of various components (i.e. hardware, software, mechanics, etc.). The final tests for the current version have all been passed and the product has been released. Shortly after, the support team receives an email from a customer complaining about the new product version. You take a look at the complaint and it becomes clear that the customer has highlighted a genuine product deficiency that wasn’t exposed during the testing. You ask yourself, what’s the solution? Is this product deficiency something that will affect all customers?
Worst case scenario – Errors detected after product release
So, it’s been established that a problem with the product needs resolving. What now? What parts of the product are affected? Which user scenarios reveal the product deficiency? Which aspects of the new product version have brought about this problem? What role has the development process played in this?
When approaching these questions, it’s crucial for the development team to have established a systematic method of working. Even if other aspects of agile development have been observed (i.e. Kanban boards), only with a systematic approach to development can customer and product requirements, which demanded the new version in the first place, be addressed quickly and efficiently.
Contexts and connections also need to be visible and traceable. You need to know which product modules are affected by the reported error. You need to be able to answer the questions: in which component can I find the module with the requirement that was the last to be implemented? In which sub-system can I find these components? As seen below in Figure 1, when connections between product components are grouped in a logical and comprehensible fashion (i.e. hierarchal), these pressing questions become easier to answer.

Fig. 1: A list comprising, among others, customer requirements and module requirements
As will be clear to anyone who has already experienced it, the later an error is found, the higher the costs are to rectify it. This alone should make you continuously assess your team’s development cycle. Furthermore, owing to the challenge of testing the quality of your product during its development, agile development processes need to be supplemented with Requirements Engineering.
How do I combine theory and practice?
When analysing, planning and implementing customer requirements, epics and stories, it’s a good idea to inspect the product architecture and, when necessary, to revise and document the sub-system, components and modules.
The theory that provides the basis for the simultaneous development of requirements and product architecture is known as the ‘twin peaks model’. This approach to development- first conceived by IT Professor Bashar Nuseibeh of the Open University- entails the concurrent realization of requirements and system architecture. The advantages of the twin peaks approach are clear to see. Upon the implementation of a customer requirement, epic or story, the repercussions and outcomes for sub-systems, components and product modules can be assessed straight away, with knowledge of the work process still fresh in mind. In turn, requirements for the sub-systems are derived from customer requirements, component requirements are derived from sub-system requirements, and module requirements are derived from component requirements. In this way, no requirement that relates to the system architecture is overlooked. If it’s found that the product architecture is insufficient for the realization and implementation of these requirements, a restructuring needs to follow. Here, new sub-systems, components or modules will have to be defined. The result: a steady refactoring for a stable and requirement-relevant product architecture.
When it comes to putting the twin peaks model into practice, you will require the right software to help you along: this is where objectiF RM comes in. With the help of this software, you can visually represent system architecture in SysML block diagrams, such as the one shown below in Figure 2, where every element of the system’s architecture is represented as a block. The hierarchal structuring of these blocks is composed of ‘aggregation relations’, which are highlighted in red. With these relation lines, it’s clearly visible which sub-systems are bound up with which components and modules. Other elements such as requirements, epics and stories are assigned to the blocks through ‘satisfy relations’, which are symbolized through grey-green lines.
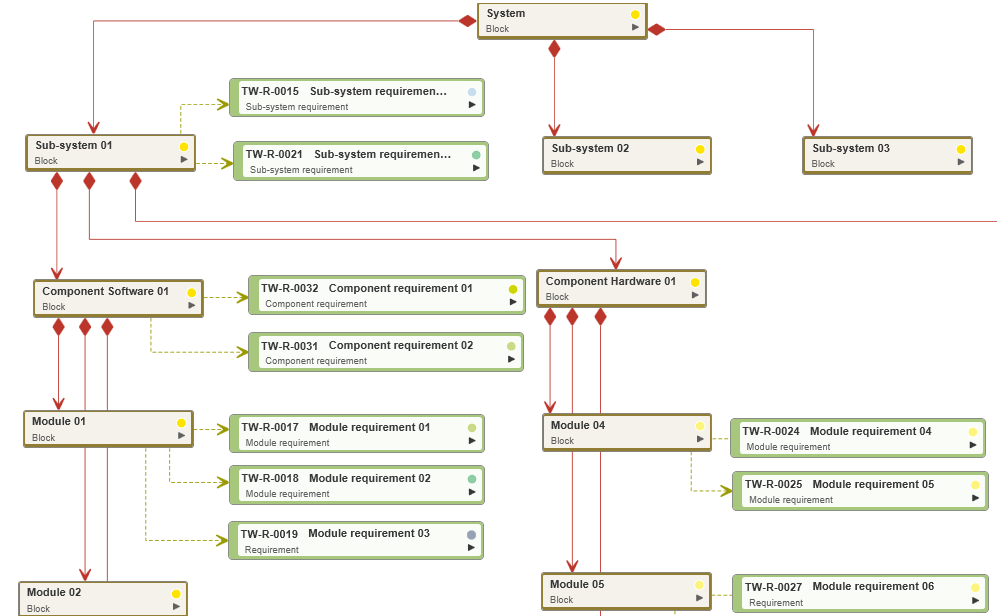
Fig. 2: Elements of a system’s architecture and their requirements displayed in a block diagram
Alternatively, you can also display architectural elements, requirements and their relations to one another in a hierarchical and configurable query table. Similar to how MS Excel works, all you need to do is define which properties are to be displayed in columns and how they should be filtered and sorted.
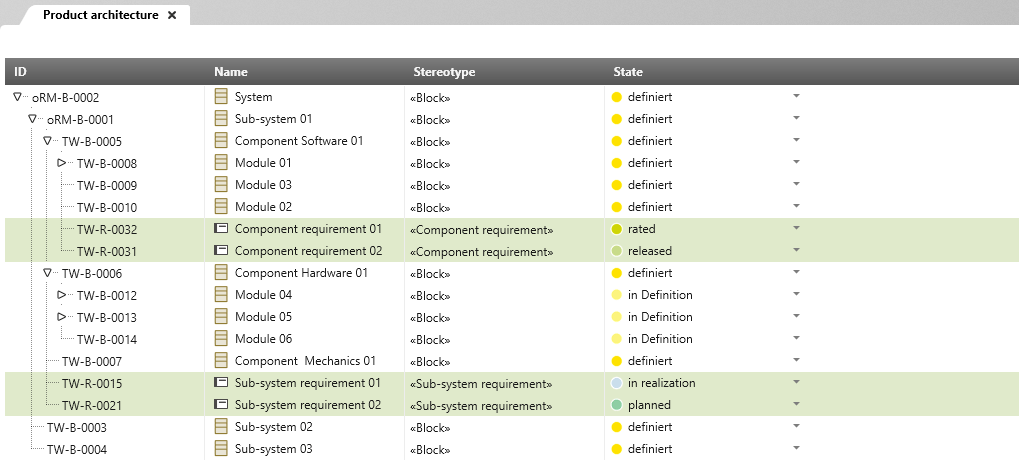
Fig. 3: Architectural elements and their requirements displayed in a hierarchical query
How can components and module requirements be derived from sub-system requirements? With objectiF RM, you are provided with backlogs for each architectural element. As shown in Figure 3, backlog views allow you to derive requirements from a higher architectural level into a lower one via drag & drop. After selecting Derive, define the requirement accordingly. These two requirements are duly bound by a ‘derive relation’, as represented in the block diagrams they are found in.
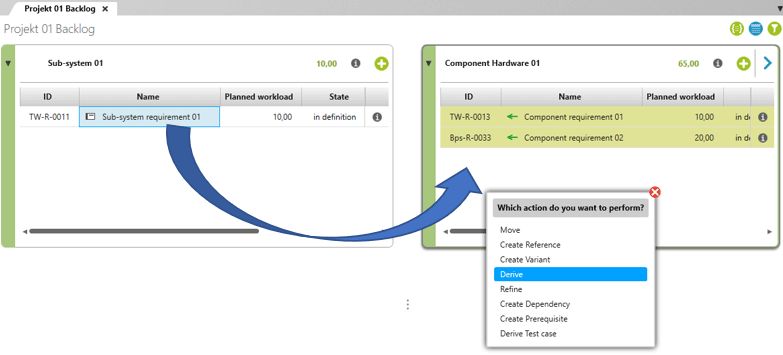
Fig. 4: Through the backlog views, create component and module requirements by deriving them from sub-system requirements
Agile and traceable?
As time goes by, the goals and requirements of customers can change. Dealing promptly with these changes is the purpose of agile development. If the intertwined relationship of system architecture and requirements had been thoroughly and clearly documented, the feasibility of applying the changes that are called for can be quickly evaluated and implemented. Furthermore, the job of estimating time and cost expenditure is made easier with fewer surprises left lurking around the corner. When it comes to applying the twin peaks model when using objectiF RM, you will not only succeed in creating a stable system architecture that remains unshaken by changing requirements but also maintain an overview of requirement locations and their dependencies. Get the free trial here.