
„Mit wem sprichst Du da?“ – Diese Frage habe ich mir in meiner Familie schon lange abgewöhnt. Ich kenne die Antworten. Sie lauten wahlweise „mit Alexa“, „mit Google“ oder einfach „mit dem Handy“. Digitale Sprachassistenten sind für uns längst alltäglich geworden. Das belegt auch die Statistik: Nach einer aktuellen Umfrage (siehe [1]) haben 60 % der Befragten in Deutschland schon einmal ein Gerät mit Hilfe einer Sprachsteuerung bedient. 92 % kennen Amazons Alexa, 77 % Googles Assistent und ebenso viele Apples Siri. Es kann deshalb nicht mehr lange dauern, bis Anwender von objectiF RPM uns fragen werden: Warum kann ich mit dem Tool nicht sprechen? Warum kann ich nicht einfach sagen: „Öffne Abfrage … Projektplan … Kanban-Board … Anforderungsdiagramm“? Oder auch: „Lege Anforderung … an“ und „Starte Videocall …“?
Diese Fragen laufen auf die Entwicklung eines digitalen Sprachassistenten für objectiF RPM hinaus, der das Arbeiten mit dem Tool einfacher und schneller macht. Die Sprachsteuerung ist der erste von drei Anwendungsfällen für KI, genauer für Machine Learning und Natural Language Processing, die wir in objectiF RPM realisieren. In meinem letzten Blog-Beitrag habe ich die drei Anwendungsfälle im Überblick vorgestellt.
Nachfolgend erfahren Sie, wie die Sprachsteuerung mit dem neuen Sprachassistenten von objectiF RPM aus Anwendersicht funktioniert und was technisch dahintersteckt. Ein kurzes Video vermittelt Ihnen einen ersten Eindruck aus dem Tool.
Drei Schritte zur Antwort
Sehen wir uns Schritt für Schritt den Weg an, den das gesprochene Wort nimmt, bis objectiF RPM ein Ergebnis präsentiert.
Sie kennen das: Um Sprachassistenten zu aktivieren, ist entweder ein Aktivierungswort oder ein spezieller Tastendruck notwendig. In objectiF RPM haben wir uns für letzteres entschieden: Nach dem Klick auf ein kleines Mikrofonsymbol kann ein Sprachbefehl eingegeben werden. Und dann startet …
Schritt 1: Speech-to-Text
Damit das Audiosignal mit der menschlichen Stimme verarbeitet werden kann, muss es zunächst in natürlichsprachlichen Text umgewandelt werden. Für diesen Vorgang der Automatic Speech Recognition (ASR) – er wird gebräuchlicher Weise als Speech-to-Text bezeichnet – können heute Services verschiedener Anbieter verwendet werden. Auch wir haben diese Möglichkeit genutzt und verwenden für Speech-to-Text Microsofts Azure Cognitive Services.
Schritt 2: Intent Recognition (Erkennen von Absichten)
Der aus den Audiosignalen erzeugte Text muss nun in eine numerische Darstellung – die sogenannten Word Embeddings – überführt werden. Für diesen Zweck wird der vortrainierte BERT Encoder von Google eingesetzt. Die erzeugten Word Embeddings sind mehr als nur Text in digitaler Form. Sie enthalten vielmehr semantische und syntaktische Informationen, die BERT aus dem Zusammenhang des Textes errechnet. Die Word Embeddings werden anschließend dafür benutzt, die Absicht des Anwenders zu analysieren.
Schauen wir genauer hin (siehe Abb. 1): Für eine Äußerung des Anwenders werden zwei Arten von Word Embeddings erzeugt: Token Embeddings für jeden Satzbestandteil und ein Sentence Embedding, das durch Mittelung aller Token Embeddings berechnet wird. Der Vorgang der Mittelwertbildung wird auch Pooling genannt. Das Pooling dient hier u.a. dazu, der vom Anwender gewünschten Aktion mehr Bedeutung gegenüber den einzelnen Satzbestandteilen zu verleihen.
Jetzt ist die ursprünglich sprachliche Äußerung also digital. Wie erkennt das System nun aber die tatsächliche Absicht des Anwenders? Hier schlägt die Stunde der Klassifizierer.
Ein Klassifizierer ist eine anwendungsfallspezifische Schicht unseres KI-Modells, also unseres neuronalen Netzes für NLP. Klassifizierer dienen dazu, Daten vordefinierten Klassen zuzuordnen. Mit den Klassifizierern beginnt unsere eigene, anwendungsfallspezifische KI-Implementierung. Die Funktion der Klassifizierer wird am besten an einem Beispiel deutlich.
Nehmen wir an, der gesprochene Satz lautet:
„Zeige die Abfrage für Anwendungsfälle im Package Anwendungsfälle.“
Hier kommen zwei Klassifizierer zum Einsatz: Der erste „kennt“ mehrere vordefinierte Klassen von Aktionen wie zum Beispiel ’create‘ und ’open‘. Diese Klassen bezeichnen wir als Intent-Typen. Eingangsinformation dieses Klassifizierers ist ein Sentence Embedding. Durch das Training mit einer Vielzahl an Beispielsätzen hat der Klassifizierer gelernt, dass Sätze, die z.B. öffne, mache auf, stelle dar und eben auch zeige enthalten, zum Intent-Typ ’open‘ gehören.
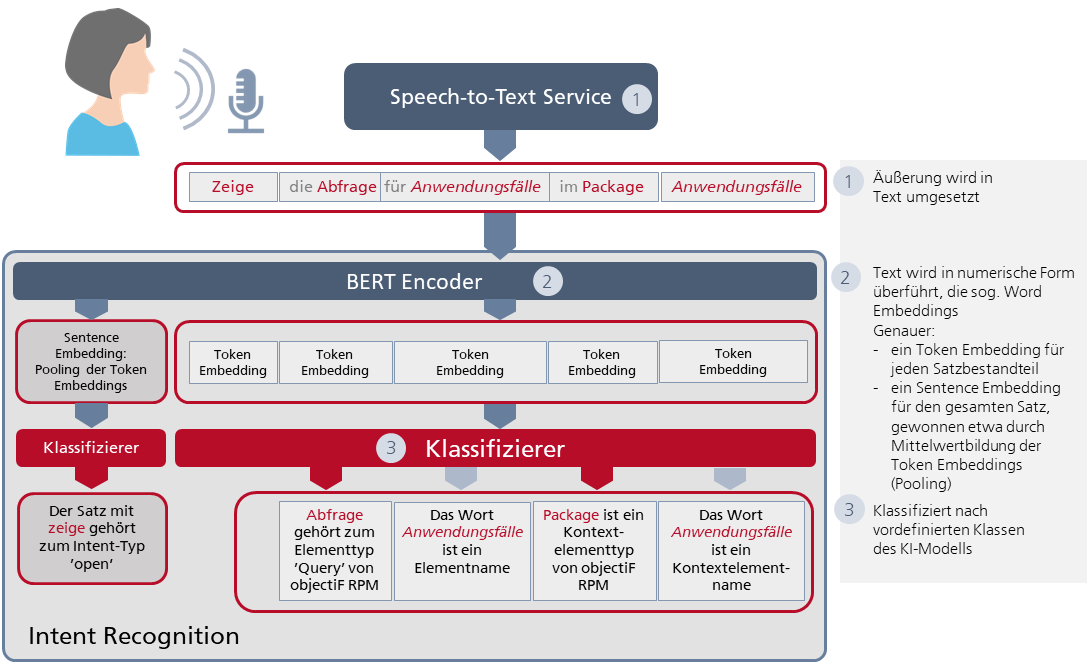
Abb. 1: Intent Recognition: Die Schichten des KI-Modells vom gesprochenen Satz bis zur erkannten Absicht des Anwenders
Um die Absicht des Anwenders zu erkennen, ist ein zweiter Klassifizierer notwendig, der die Token Embeddings verarbeitet. Er kann Eingaben nach den Elementtypen von objectiF RPM wie ’Query‘, ’Diagram‘, ’GanttChart‘, ’KanbanBoard‘, ’Dashboard‘ etc. klassifizieren. Durch Training hat er anhand vieler Beispiele unter anderem gelernt, dass Abfrage zum Elementtyp ’Query‘ gehört – genau wie Auswertung und Auflistung. Elemente kommen in objectiF RPM jeweils in einem speziellen Kontext vor. Sie liegen zum Beispiel in einem bestimmten Package oder stammen aus einem Projekt. Der Klassifizierer „kennt“ deshalb auch Kontextelementtypen wie ’Package‘ oder ’Project‘.
Was haben wir am Ende des Schrittes Intent Recognition erreicht? Beantworten wir diese Frage anhand des Beispiels: objectiF RPM könnte jetzt versuchen, in seinem Repository eine Abfrage zu öffnen, die Anwendungsfälle heißt und in einem Package liegt, das ebenfalls den Namen Anwendungsfälle besitzt. Vielleicht haben wir Glück und die verwendeten Namen kommen im Repository von objectiF RPM tatsächlich vor. Aber in sehr vielen Fällen kennt der Anwender die Namen nur so ungefähr. Und so ist es auch in unserem Beispiel. Im Video werden Sie sehen, dass es keine Abfrage Anwendungsfälle gibt, aber eine Abfrage Anwendungsfallliste. Damit objectiF RPM auch dann Ergebnisse liefert, wenn der Anwender nicht die exakten, sondern nur „so ähnliche“ Begriffe verwendet, ist ein weiterer Schritt notwendig.
Schritt 3: Semantic Similarity (Semantische Ähnlichkeit)
Mit Hilfe des KI-Systems muss ermittelt werden, ob es zu den erkannten Element- bzw. Kontextelementnamen aus der Äußerung des Anwenders im Repository von objectiF RPM ähnliche – im besten Fall gleiche – Namen gibt. Dabei ist zu beachten, dass in objectiF RPM Element- und Kontextelementnamen jeweils aus mehreren Wörtern bestehen können. Wir brauchen also ein weiteres KI-Modell, das für die zu vergleichenden Wortfolgen jeweils eine numerische Darstellung liefert, die dann dazu benutzt werden kann, die semantische Ähnlichkeit der Wortfolgen zu errechnen.
Genau dafür gibt es eine Lösung, auf die wir als „Fertigteil“ zurückgegriffen haben: das vortrainierte Sentence-BERT, kurz SBERT. Es wurde gerade mit der Absicht entwickelt, die ursprüngliche BERT-Architektur u.a. für die Ermittlung semantischer Ähnlichkeit zu optimieren.
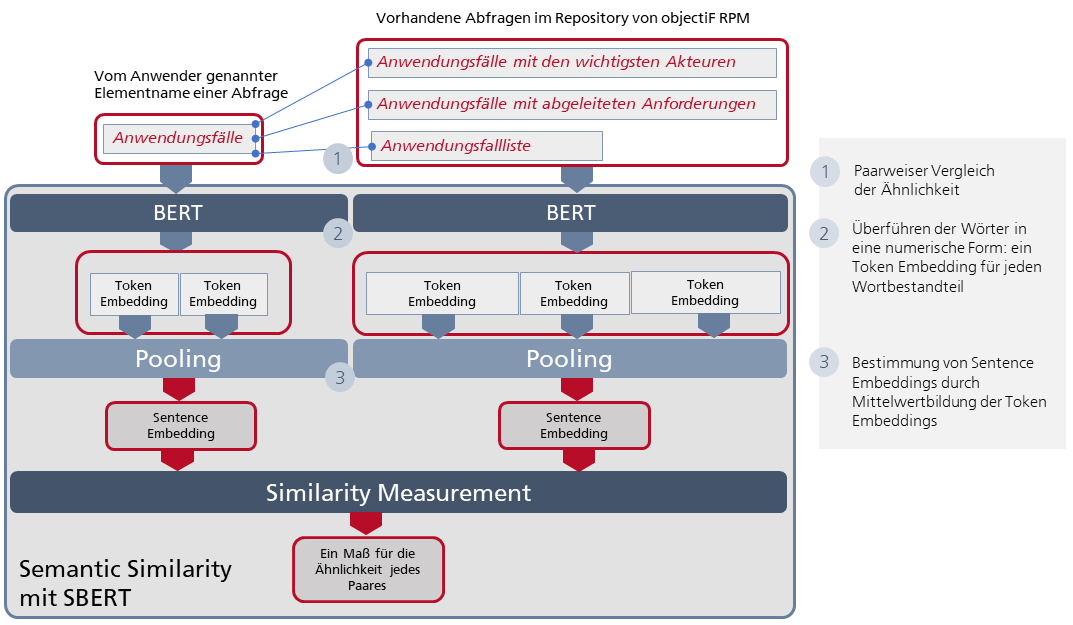
Abb. 2: Semantic Similarity: Die Schichten des KI-Modells zum Erkennen von semantischer Ähnlichkeit zwischen den vom Anwender verwendeten Worten und den Namen im objectiF RPM Repository
Das Besondere an SBERT (siehe Abb. 2) ist, dass zwei BERT-Modelle parallel eingesetzt werden können: in unserem Fall eines für den jeweiligen Element- bzw. Kontextelementnamen und ein zweites für die damit zu vergleichenden Namen aus dem objectiF RPM Repository. Jedes dieser BERT-Modelle liefert pro Wort der eingegebenen Wortfolgen eine numerische Darstellung. Ich will hier wieder von einem Token Embedding sprechen. Aus den Token Embeddings wird durch eine Mittelwertbildung, also durch ein Pooling, eine Art Sentence Embedding errechnet. (Ich bleibe bei dieser Begriffsbildung, auch wenn Wortfolgen wie „Anwendungsfälle mit abgeleiteten Anforderungen“ keine „richtigen“ Sätze sind.) Mit dem Sentence Embedding des vom Anwender verwendeten Element- bzw. Kontextelementnamens und den einzelnen Sentence Embeddings der Namen aus dem Repository wird ein Wert für ihre Ähnlichkeit berechnet. Die anspruchsvolle Mathematik dahinter sparen wir uns hier. Stellen wir uns einfach eine Blackbox vor (in Abb. 2 als Similarity Measurement bezeichnet), die als Ergebnis ein Maß für die Ähnlichkeit zwischen der vom Anwender gewählten Formulierung und den tatsächlichen Namen im Repository liefert. Sehen wir uns – statt komplexer Formeln – lieber an, wie das Ganze in der Praxis funktioniert:
Übrigens, die im Film verwendeten Imperativsätze, die alle mit einem Verb beginnen, könnten zu der Vermutung führen, dass der Anwender immer einen festen Satzaufbau einhalten muss. Das ist natürlich nicht der Fall. Das KI-System wird mit vielen Beispielsätzen unterschiedlicher Struktur trainiert, damit es auch bei Äußerungen mit einem anderen Aufbau funktioniert wie „Die Liste der Stakeholder mit Anforderungen im Package der Anforderungsanalyse öffnen“ oder „Aus den Projektauswertungen den Projektplan als Gantt Chart holen“.
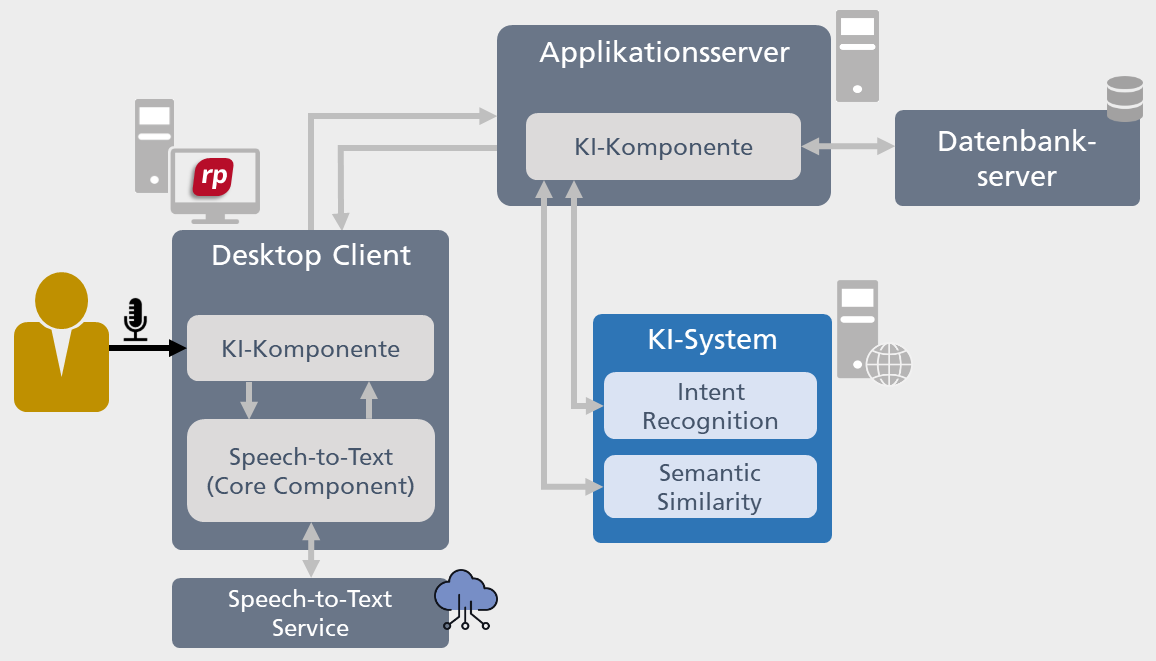
Die erweiterte Architektur von objectiF RPM
Das beschriebene KI-System muss in die Client-/Server-Architektur von objectiF RPM integriert werden. Einen Überblick darüber, wie sich die neuen Komponenten in die Tool-Architektur einfügen, zeigt die nachfolgende Abbildung.
So viel zum Sprachassistenten. Im nächsten Beitrag stelle ich Ihnen den zweiten Anwendungsfall für KI in objectiF RPM vor. Er rückt die Qualität von Requirements in den Fokus. Konkret geht es darum, wie KI-Funktionen genutzt werden können, um die Verständlichkeit von Anforderungen in objectiF RPM zu verbessern. Wenn Sie das Tool bisher noch nicht kennen, probieren Sie es doch einfach einmal aus. Hier geht es zum kostenlosen Download.
Quelle:
[1] https://de.statista.com/themen/4271/digitale-sprachassistenten/#dossierKeyfigures, abgerufen am 03.02.2022