
„Ich kann Sie nicht verstehen.“ Wieder und wieder sagte die künstliche Stimme diesen Satz – auf der ersten CeBIT 1986. Es war nicht zu überhören: Das System streikte. Auch während des obligatorischen Messerundgangs der Polit-Prominenz. Peinlich für den Anbieter des Systems, ein Startup-Unternehmen neben uns auf dem Gemeinschaftsstand des Berliner Innovations- und Gründerzentrums und der TU. Was für uns nur nervtötend war, muss die Betroffenen fast zur Verzweiflung getrieben haben. Nach diesem Erlebnis war klar: Künstliche Intelligenz (KI), speziell Spracherkennung war (noch) keine Option für uns.
Vom nächsten Annäherungsversuch an KI ein paar Jahre später zeugt nur noch ein vergilbtes Buch in unserer Bibliothek. Das Thema: Expertensysteme – Regelbasierte Lösungen mit PROLOG. Spannend, aber im Kontext unserer damaligen Produkte fanden wir keinen geeigneten Anwendungsfall, den wir mit unseren Möglichkeiten hätten implementieren können.
Heute, wo wir von Sprachassistenten umgeben sind, unser „Home“ immer smarter wird, wir durch Gesichtserkennung identifiziert werden, Social Media, E-Commerce und Online Marketing, HR und viele andere Bereiche sich KI zunutze machen, ist es an der Zeit, das Thema wieder aufzugreifen.
Anfang 2020 startete microTOOL ein KI-Vorhaben. Inzwischen haben wir Know-how aufgebaut, die Chancen für KI-basierte Features für objectiF RM und objectiF RPM ausgelotet, Anwendungsfälle identifiziert, ihre Machbarkeit untersucht und Prototypen implementiert. Zum Zeitpunkt der Veröffentlichung dieses Beitrags wird der erste Anwendungsfall gerade realisiert.
Zielsetzung für KI-Unterstützung in objectiF RM und objectiF RPM
Das sind unsere Ziele: objectiF RM und objectiF RPM werden mit Funktionen des Machine Learning ausgestattet, um
- die Arbeit mit den Tools einfacher und schneller zu machen,
- die Qualität der Ergebnisse schwerpunktmäßig im Bereich des Requirements Engineering zu verbessern.
Dafür haben wir diese drei Anwendungsfälle definiert:
- Anwendungsfall 1: Durch die Möglichkeit zur Sprachsteuerung soll die Bedienung der Tools noch leichter werden. Die Benutzerfreundlichkeit soll steigen. Dieser Anwendungsfall umfasst die Umwandlung Speech-to-Text (Automatic Speech Recognition), das Erkennen der formulierten Absicht des Users (Intent Recognition) und ihre Ausführung.
- Anwendungsfall 2: Zu kurz, zu lang, unvollständig oder total überfrachtet – syntaktischen Eigenschaften beeinträchtigen die Verständlichkeit von Anforderungen. KI soll Ihnen helfen, die Ergebnisse des Requirements Engineering in dieser Hinsicht qualitativ zu verbessern.
- Anwendungsfall 3: Große System können Hunderte, ja Tausende von Anforderungen besitzen. Wie können Sie sicher sein, dass neue Anforderungen nicht schon in ähnlicher Form existieren? KI soll Sie dabei unterstützen, semantische Ähnlichkeit von Anforderungen zu identifizieren.
Requirements Engineering ist eine sprachliche Aufgabe. Das Vokabular ist z.B. in der Medizintechnik ein ganz anderes als – sagen wir – im Automotive-Sektor. Daraus ergibt sich zusätzlich zu den drei Anwendungsfällen eine weitere Herausforderung: Wenn KI Sie beim Requirements Engineering unterstützen soll, muss die Lösung Ihre branchen- bzw. domänenspezifische Sprache „erlernen“ können.
Jeden Anwendungsfall werde ich in einem eigenen Blog-Beitrag beschreiben. Zum Verständnis dieser Folgebeiträge sind einige begriffliche Grundlagen notwendig, die ich nachfolgend legen werde. Abschließend stelle ich Ihnen die Technologie vor, die wir für unsere KI-Features nutzen.
Begriffliche Grundlagen
In allen drei Anwendungsfällen geht es um die Verarbeitung und das Verstehen von natürlicher Sprache. Wir bewegen uns damit auf dem Gebiet von Natural Language Processing (NLP), einer Disziplin an der Schnittstelle von Informatik, KI und Linguistik.
Mit welchen Mitteln wollen wir unsere spezifischen NLP-Probleme lösen? Sehen wir uns unter diesem Aspekt das weite Feld der KI näher an.
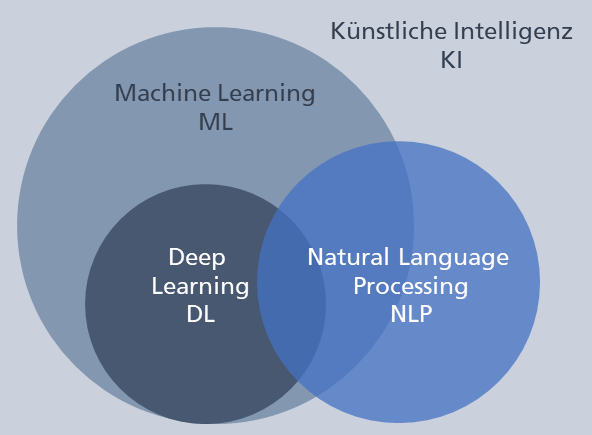
Abb. 1: Der Zusammenhang der Disziplinen KI, ML, DL und NLP
Wir bewegen uns bei der Realisierung unserer Anwendungsfälle im Bereich Machine Learning (ML), genauer im Teilbereich Deep Learning (DL).
ML beschäftigt sich mit der Entwicklung von Algorithmen, die anhand einer großen Zahl von Beispielen lernen können, Aufgaben automatisch auszuführen, ohne dass dazu explizite Instruktionen erforderlich sind.
DL bezeichnet den Teilbereich des maschinellen Lernens, der auf einer Schichtenarchitektur aus künstlichen neuronalen Netzen basiert.
Formen des maschinellen Lernens
Man kann drei Formen des maschinellen Lernens unterscheiden:
- Überwachtes Lernen. Hier wird dem System anhand von zahlreichen Beispielen in Form von Input-Output-Paaren vorgegeben, was erlernt werden soll. Die Output-Daten werden auch als Labels oder Grundwahrheiten bezeichnet.
- Unüberwachtes Lernen. Das System versucht hierbei eigenständig – ohne Referenz-Output – in den bereitgestellten Input-Daten verborgene Muster und Regelmäßigkeiten zu finden.
- Bestärkungslernen. Das System – hier Agent genannt – führt Aktionen aus. Auf jede Aktion reagiert die Umwelt. Der Agent erhält Informationen über den erreichten Zustand und ggf. eine Belohnung. Ziel ist es, dass der Agent eine Strategie für seine Aktionen entwickelt, mit der er auf beliebige Zustände so reagieren kann, dass er in der Summe eine möglichst hohe Belohnung erhält.
Für unsere drei Anwendungsfälle verwenden wir die gängigste der drei Formen, das überwachte Lernen.
Das Prinzip des Trainings beim überwachten Lernen
Wie lernt ein Modell, das aus mehreren Schichten von künstlichen neuronalen Netzen besteht? Es lernt anhand von Beispieldaten – sehr, sehr vielen Beispieldaten. Sie werden auch als Trainingsdaten bezeichnet. Lernen bedeutet hier also das Trainieren eines Modells.
In unseren drei Anwendungsfällen haben wir es immer mit natürlichsprachlichem Text zu tun. Das Problem: Natürliche Sprache ist komplex, unstrukturiert und mehrdeutig. Die natürlichsprachlichen Trainingssätze müssen zunächst in eine numerische Repräsentation transformiert werden. Die so gewonnenen Trainingsdaten können dann für das maschinelle Lernen verwendet werden.
Das Trainieren eines Modells läuft beim überwachten Lernen – stark vereinfacht (!) – nach dem folgenden Prinzip ab:
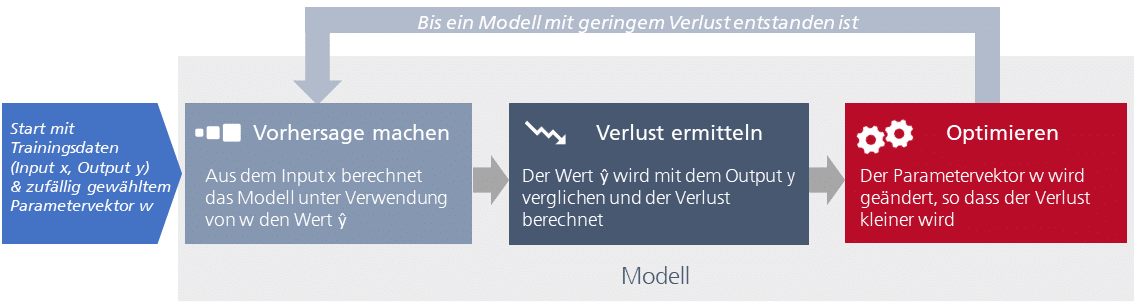
Abb. 2: Maschinelles Lernen – das Prinzip des Trainings
Um ein Modell zu trainieren, werden zunächst Trainingsdaten benötigt, die jeweils aus einer Eingabe x und der zugehörigen korrekten Ausgabe (der Grundwahrheit) y bestehen. Beim Trainieren soll ein initiales Modell verbessert werden. Deshalb wird noch etwas gebraucht: ein Parametervektor w, der die Modelleigenschaften widerspiegelt. Zu Beginn des Trainings wird der Parametervektor willkürlich gewählt. Im Verlauf des Trainings wird er schrittweise so angepasst, dass das Modell die geforderte Aufgabe immer besser meistert. Das sind die grundlegenden Schritte des Trainings:
Schritt 1 – Vorhersage machen: Aus der Eingabe x und den zu Beginn noch zufälligen Modelleigenschaften in Form des Parametervektors w erstellt das Modell eine Prognose ŷ für den Ausgabewert.
Schritt 2 – Verlust ermitteln: Das Modell berechnet, wie weit der Prognosewert ŷ von der erwarteten Ausgabe y abweicht. Diese Abweichung wird Verlust (Loss) genannt.
Schritt 3 – Optimierung: Das Modell ändert nun selbstständig den Parametervektor mit dem Ziel, den Verlust zu verringern.
Mit dem veränderten Parametervektor werden diese Schritte erneut durchlaufen – immer wieder, so lange, bis der Verlust nicht mehr verbessert werden kann. Ist dieser Zustand erreicht, werden die Werte des Parametervektors gespeichert. Das Modell ist trainiert. Es ist bereit für den Einsatz.
Technische Grundlagen
Anders als bei unseren ersten Annäherungsversuchen an KI können wir heute auf eine große Menge an Public Know-how im Bereich Deep Learning Modelle für NLP zugreifen und „Fertigteile“ für die Implementierung verwenden.
Für die erste Aufgabe, die im Kontext unserer Anwendungsfälle zu lösen ist, also für das Überführen der natürlichsprachlichen Trainingssätze in eine numerische Repräsentation, die sogenannten Word-Embeddings, haben wir uns für den Einsatz des BERT Modells von Google entschieden. Es wurde 2018 von Jacob Devlin und seinen Mitstreitern bei Google veröffentlicht und wird u.a. für die Google Suche angewendet.
BERT steht für Bidirectional Encoder Representations from Transformers. Wie der Name sagt, ist BERT im Kern ein sogenanntes Transformer-Modell. Transformer Modelle eignen sich besonders gut für NLP-Aufgaben, weil sie dadurch gekennzeichnet sind, dass sie den Kontext eines eingegebenen Wortes berücksichtigen können. (Das Standardbeispiel dafür: Im Kontext mit „sitzen auf“ ist mit dem Wort „Bank“ sicher nicht das Geldinstitut gemeint.)
Das Trainieren eines Modells für die Verarbeitung von natürlicher Sprache erfordert extrem umfangreiche Trainingsdaten und ein langwieriges Training. Damit wird das Trainieren zu einem relevanten Kostenfaktor bei der Entwicklung von KI-Anwendungen. Wir haben uns auch deshalb für den Einsatz von BERT entschieden, weil es ein vortrainiertes Modell mit umfangreichem Vokabular und entsprechenden Parametern ist.
Die grundlegende Architektur
BERT ist die Basis, aber noch lange nicht die Lösung für unsere drei Anwendungsfälle. Sie erfordert:
- eine gesamtheitliche Modellarchitektur
- anwendungsfallspezifisches Training
- feature-mäßige Integration in objectiF RM und objectiF RPM.
Mit einem Blick auf die Modellarchitektur und das erforderliche Training möchte ich diesen Beitrag abschließen:
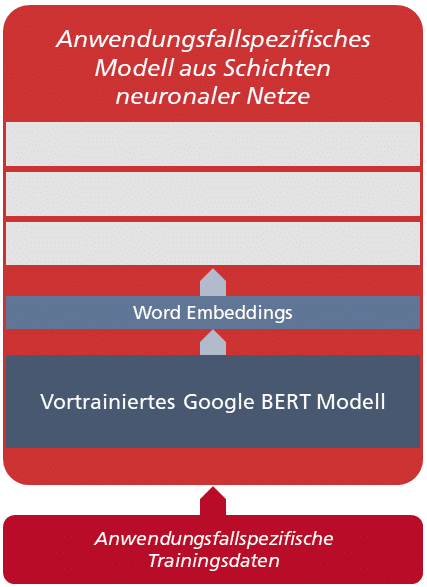
Abb. 3: Einheitliche Modellarchitektur für die ausgewählten Anwendungsfälle
Jeder Anwendungsfall erfordert ein eigenes Modell aus Schichten neuronaler Netze im Sinne von Deep Learning, das jeweils mit anwendungsfallspezifischen Daten trainiert wird. Zu jedem anwendungsfallspezifischen Modell gehört ein BERT Modell, das mit allgemeinem und domänenspezifischem Vokabular vortrainiert ist. Es digitalisiert die Trainingsdaten, erzeugt also die Word-Embeddings.
Die anwendungsfallspezifischen Modelle werden von microTOOL mit TensorFlow, einem Framework zur datenstromorientierten Programmierung, das ursprünglich von Google stammt, unter Verwendung der Library Official.NLP, ebenfalls von Google, implementiert.
Im nächsten Beitrag werfen wir einen genaueren Blick auf den ersten Anwendungsfall, die Sprachsteuerung speziell für objectiF RPM. Wenn Sie das Tool bisher noch nicht kennen, schauen Sie es sich doch einmal näher an. Hier geht es zum kostenlosen Download.
Quellen:
Der Beitrag orientiert sich bei der Begriffsbildung an: Sowmya Vajjala et al.: Practical Natural Language Processing. 1. Auflage. O’Reilly Media, 2020