
Wenn Sie mit Anforderungsmanagement im Automotive-Sektor zu tun haben, dann wissen Sie, dass die pure Menge an Anforderungen hier zu den größten Herausforderungen zählt. Für die Software sowie die Elektrik/Elektronik eines gut ausgestatteten Mittelklassewagens kommen etwa 450.000 (kein Tippfehler!) Anforderungen zusammen. Dazurechnen muss man noch einmal ca. 50.000 Anforderungen an die Mechanik und solche, die sich aus Normen und gesetzlichen Vorschriften ableiten (zum Mengengerüst siehe [1]). Für Zulieferer in der Automobilindustrie bedeutet das, sie müssen mit zigtausend Anforderungen an ihre Produkte umgehen können – und mit folgender Situation: Wenn ein Automobilhersteller neue Anforderungen an ein Produkt eines Zulieferers stellt, muss letzterer sicher gehen können, dass in seinem großen Bestand an Produktanforderungen nicht bereits inhaltlich ähnliche vorkommen, die vielleicht sogar schon realisiert sind.
Das Problem: Die Sprache ist vielfältig. Es gibt unzählige Möglichkeiten, dasselbe zu sagen. Wie erkennt man also inhaltlich ähnliche Anforderungen? Algorithmisch ist das Problem in dieser Größenordnung nicht zu lösen. Hier schlägt die Stunde der Künstlichen Intelligenz (KI).
Dieser Anwendungsfall für KI, genauer für Machine Learning (ML) und Natural Language Processing (NLP), gehört zu denen, die wir in der Unternehmenssoftware objectiF RPM realisieren. In einem früheren Blog-Beitrag habe ich sie Ihnen bereits im Überblick vorgestellt. Nachfolgend erfahren Sie, wie unsere KI-Lösung für diesen Anwendungsfall – also für das Erkennen von ähnlichen Anforderungen in großen Anforderungsmengen – im Detail funktioniert.
Was heißt denn eigentlich „ähnlich“?
Wenn man ein KI-System entwickeln will, das ähnliche Anforderungen erkennt, dann benötigt man als erstes ein gemeinsames Verständnis davon, was Ähnlichkeit bedeutet. Außerdem muss man festlegen, wie Ähnlichkeit gemessen werden soll.
Die Ähnlichkeit zweier Anforderungen entsteht durch eine Reihe von semantischen und syntaktischen Merkmalen, z.B. dadurch, dass sie Synonyme enthalten und dass der Satzaufbau gleichartig ist. Hier ein paar Beispiele:
Die Anforderungen Das System muss die Nachricht speichern und Die Software muss die Nachricht speichern sind sehr ähnlich. Sie stimmen im Satzaufbau, dem Prädikat und dem Objekt überein. Mehr noch: Die Subjekte System und Software der beiden Sätze sind zwar verschieden, können aber synonym verwendet werden.
Die Anforderungen Das System muss die Nachricht speichern und Das System muss die Dokumente ablegen haben gleiche Satzteile, aber Nachricht speichern und Dokumente ablegen sind nicht synonym. Diese Anforderungen sind nur teilweise ähnlich.
Die Anforderungen Das System muss die Nachricht speichern und Das Team muss das Release bereitstellen stimmen zwar im Satzaufbau und im Modalverb muss überein, sind aber sonst ziemlich unterschiedlich.
Wie wird Ähnlichkeit gemessen?
Wie kann ein KI-System vorhersagen, wie ähnlich zwei Anforderungen sind? Damit das überhaupt funktioniert, müssen die natürlichsprachlichen Anforderungen in eine digitale Form umgesetzt werden. Da Ähnlichkeit, wie die obigen Beispiele zeigen, durch vielfältige Aspekte entsteht, wird als digitale Darstellung für eine Anforderung jeweils ein Vektor erzeugt. Ein solcher Vektor wird als Sentence Embedding bezeichnet. Der Abstand von Vektoren kann mathematisch bestimmt werden. Je geringer der Abstand zweier Sentence Embeddings ist, umso ähnlicher sind die Anforderungen.
Wir haben uns entschieden, die ermittelten Abstände auf eine Skala zwischen 0 – sehr ähnlich bis 1 – überhaupt nicht ähnlich zu projizieren.
So lernt das KI-System
Für das Training wird ein sogenanntes Siamesisches Modell verwendet. Es verarbeitet jeweils Anforderungspaare. Jede Anforderung eines solchen Paares wird von einem sogenannten Sentence Modell verarbeitet.
Das Sentence Modell besitzt eine Schichtenarchitektur. Die oberste Schicht bildet der Universal Sentence Encoder von Google – ein für 16 Sprachen vortrainiertes ML-Open-Source-Modell. Es liefert für jede eingegebene natürlichsprachliche Anforderung ein Sentence Embedding, also eine digitale Darstellung in Form eines Vektors und zwar der Dimension 512. Dieser Vektor wird in der nächsten Schicht – bestehend aus mehreren von uns entwickelten Projection Layers – zu einem Vektor der Dimension 64 verdichtet. Warum? Grob gesagt, weil auf diese Weise die „spannenden“ – also die bedeutsamen – Koordinaten der Embedding-Vektoren ein höheres Gewicht bekommen als die „langweiligen“, die für den Vergleich auf Ähnlichkeit keinen wesentlichen Beitrag leisten.
Dieser Vergleich findet in einem ebenfalls von uns entwickelten Distance Layer statt. Das Ergebnis ist eine Vorhersage für die Ähnlichkeit in Form eines Wertes zwischen 0 und 1. Wie gut diese Vorhersage ist, zeigt der Vergleich mit dem pro Trainingssatz mitgegebenen Zielwert. Im Laufe des Trainings lernt das Siamesische Modell, den Verlust zu minimieren, d.h. für ähnliche Anforderungen den Abstand der Vektoren zu verkleinern bzw. für unterschiedliche zu vergrößern.
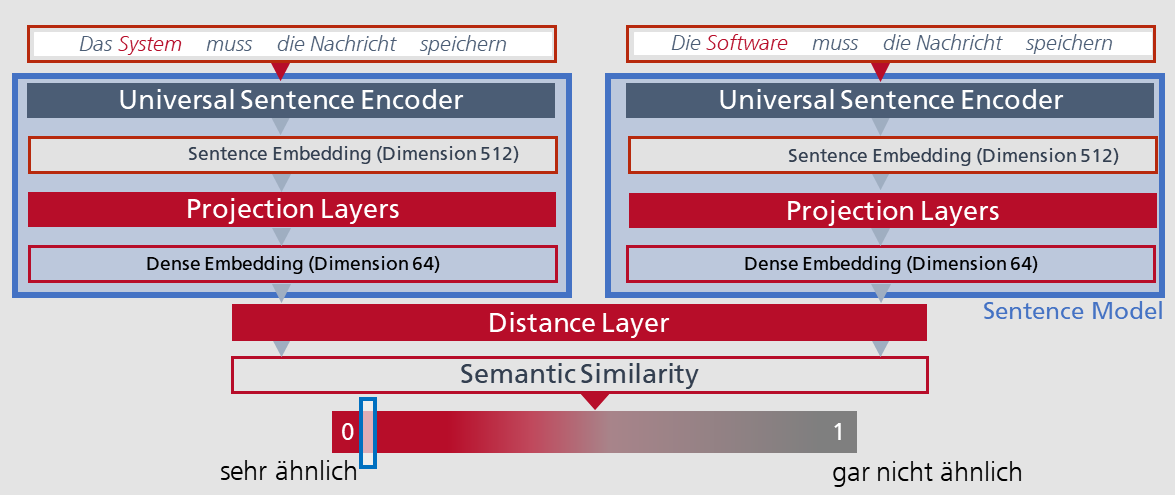
Abb. 1: Die Architektur für das Training zum Erkennen von ähnlichen Anforderungen
Nach dem Training mit vielen tausend Trainingsdaten kann das Sentence Modell prinzipiell in Betrieb gehen. So kann es z.B. in der anfangs beschriebenen Situation eines Automobilzulieferers eingesetzt werden, um für neue Anforderungen seiner Kunden zu prüfen, ob diese im Bestand der Produktanforderungen möglicherweise in ähnlicher Form schon vorhanden sind. Was das Sentence Modell im Einsatz leistet, zeigt ein Blick auf einen Entwickler-Bildschirm.
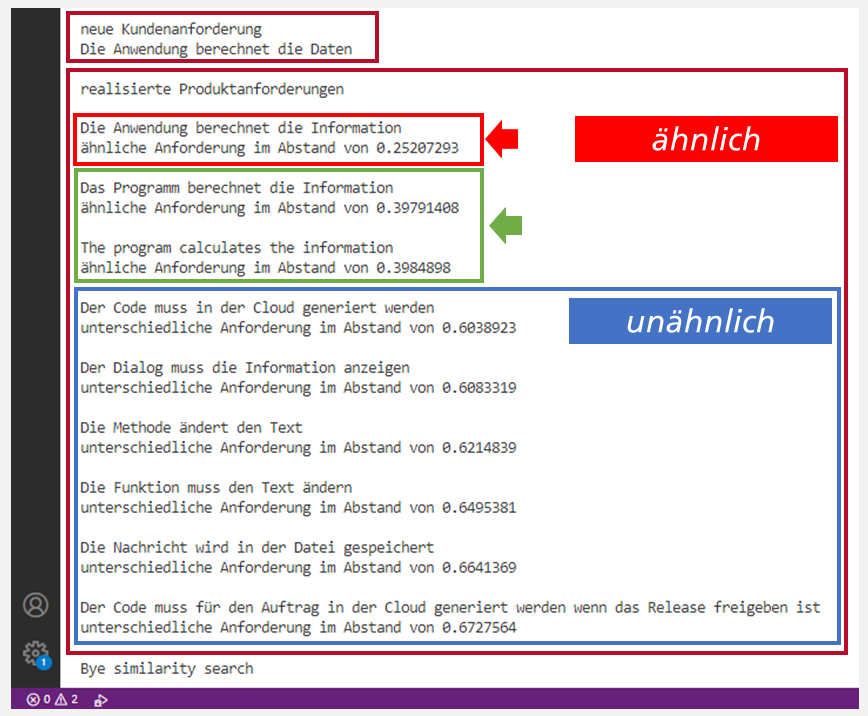
Abb. 2: Dieser Screenshot vom Terminal-Fenster in MS Visual Studio Code zeigt für eine neue Kundenanforderung die gefundenen ähnlichen Anforderungen im Anforderungsbestand. Das KI-System liefert jeweils ein Maß für die Ähnlichkeit. Je kleiner der Wert, umso höher ist die Ähnlichkeit. Übrigens, auch englische Anforderungen oder ein wenig Denglisch bringt das Sentence Modell nicht dem Konzept.
Grundsätzlich könnte die KI-Lösung – basierend auf dem Sentence Modell – in objectiF RPM integriert und mit einer benutzerfreundlichen Oberfläche versehen werden. So wird man als Anwender von objectiF RPM vorgeben wollen, ab welchem Grad an Ähnlichkeit Anforderungen zur Überprüfung ausgegeben werden sollen. Die vom integrierten KI-System ermittelten ähnlichen Anforderungen werden dann zur Nachbearbeitung in Form einer Auswertung aufgelistet, wie sie in objectiF RPM üblich ist.
Allerdings: Da ist noch ein Haken bei der Sache. Will man jede neue Anforderung mit jeder der zigtausend vorhandenen vergleichen, dann sind Performance-Probleme sehr wahrscheinlich. Eine performance-optimierte Lösung muss also her.
Die Architektur für den Einsatz mit objectiF RPM
Wir haben uns entschieden, für die KI-basierte semantische Suche von ähnlichen Anforderungen, die in objectiF RPM integriert werden soll, die Open-Source Vektordatenbank Milvus einzusetzen. Sie ist speziell für das Verwalten von Embeddings – also Vektoren – aus ML-Systemen konzipiert.
Und so funktioniert die datenbankbasierte KI-Lösung: Für den gesamten Bestand an Produktanforderungen werden mit dem trainierten Sentence Modell die zugehörigen Sentence Embeddings erstellt. Sie werden zusammen mit den IDs der Anforderungen in der Vektordatenbank gespeichert. Jede neue Kundenanforderung wird ebenfalls durch das Sentence Modell „geschickt“, um einen Vektor zu erzeugen. Hier sprechen wir von einem Query Embedding. Mit dem Query Embedding werden in der Datenbank alle Sentence Embeddings mit möglichst geringem Abstand gesucht. Über ihre IDs können dann die zugehörigen Produktanforderungen „im Klartext“ ermittelt werden.
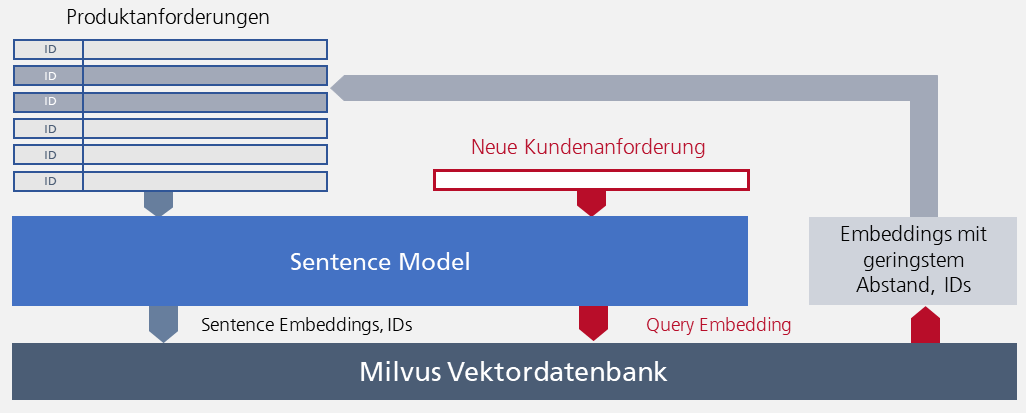
Abb. 3: Die Architektur der datenbankbasierten KI-Lösung für den Einsatz mit objectiF RPM
Zu guter Letzt …
… das Beste an dieser Lösung: Sie ist nicht nur auf Anforderungen anwendbar, sondern auch auf User Stories, Testfälle, Bugs … – kurz auf alles, von dem es im Requirements Engineering, Testmanagement, der Entwicklung und anderen Unternehmensprozessen viel gibt.
Und damit ergeben sich noch viele weitere Möglichkeiten für den Einsatz von KI in objectiF RPM. Übrigens: Wenn Sie das Tool bisher noch nicht kennen, probieren Sie es doch einfach einmal aus. Hier geht es zum kostenlosen Download.
Quelle:
[1] Siemens Digital Industries Software: Whitepaper Orchestrieren der Entwicklung von eingebetteten Anwendungen in der Automobilbranche: Definition und Planung von Anwendungen, 2019