
“Sorry, I’m having trouble understanding you right now.” Nowadays, when using Artificial Intelligence technology (AI) such as Siri or Alexa, this is a sentence many hear on a day-to-day basis. As frustrating as it is to hear these fateful words, there is usually a reasonable explanation for AI not being quite as intelligent as we might have hoped. It hasn’t, however, always been like this.
My own experiences with AI began in 1986. It was the first CeBIT, and the voice of AI could do nothing more than state “I can’t understand you.” Like us, the start-up that had created the AI system was part of the joint stand for the Berlin Innovation and Start-Up Centre and Technical University, and their product was on permanent strike. What was merely annoying for the other attendees of the conference must have been devastating for the AI start-up. What we took away from this experience all those years ago was that AI, especially speech recognition, was a long way from becoming a viable option for microTOOL. The next stages of AI’s development, such as rule-based solutions with PROLOG, were exciting, however, were still yet to reach the point where we thought that they would seamlessly reshape our tools for the better. Many tech firms held the same opinion.
Today, AI is ubiquitous at home and in the office. Everywhere you look, you are surrounded by technology that can recognize your face, react to what you say, read your fingerprints, suggest adverts that suit your tastes etc. Without AI, social media, e-commerce, and online marketing wouldn’t be nearly as effective as they are.
In light of these giant steps forward that have been taken on the path of AI, we at microTOOL thought that it was the right time to integrate AI into our products. That’s why, in 2020, we launched our very own AI project. Since then we have built up our know-how, as well as explored the opportunities AI features have to offer for objectiF RM and objectiF RPM. We have also identified use cases, assessed their feasibility and built prototypes. At the current time of writing, we are realizing our first use case.
Objectives for AI Support within objectiF RM and objectiF RPM
Our main goal regarding AI is for objectiF RM and objectiF RPM to be equipped with machine learning functions. This entails:
- Easier and quicker work processes and
- Improved quality of results in Requirements Engineering.
For these intents and purposes, we have developed three use cases for AI in objectiF RM and objectiF RPM:
- Use case 1: Develop voice control to make use of the tools easier and increase user-friendliness. This includes speech-to-text and automatic speech recognition, as well as recognizing the intent of the user and correctly predicting the tasks that should be performed.
- Use case 2: Whether or not they are too long, short, vague or overly detailed, syntactic properties can obscure the comprehensibility of stakeholder requirements. AI should bring more clarity for the purposes of Requirements Engineering.
- Use case 3: Large systems can have hundreds or even thousands of requirements. This means that it’s easy to fall into the trap of only viewing them at a high level of abstraction, losing an understanding of the specifics of each requirement along the way. This runs the risk of requirements being defined multiple times with only slight variations. AI should help you to identify similar semantic properties of requirements, allowing you to trim away unnecessary reiterations of requirements, thus saving energy and resources.
In its essence, Requirements Engineering is a work process centred around linguistics. This is because its success depends to a large extent on understanding and adapting to the technicalities and singularities of each respective field’s internal vocabulary. A software system, for example, built for a pharmaceutical company would require a completely different lexicon than one for a car manufacturing company. In the context of AI, the great challenge is to learn these industry-specific lexicons.
The three use cases mentioned above will be discussed in more depth as separate articles, which will form a mini-series on AI. To understand these use cases, however, a basic introduction is necessary, which the rest of this article will provide. It will also introduce the AI features that we are currently integrating into our tools.
Conceptual Basics
All three of our use cases are based around Natural Language Processing (NLP). This is a discipline that combines computer science, AI and linguistics.
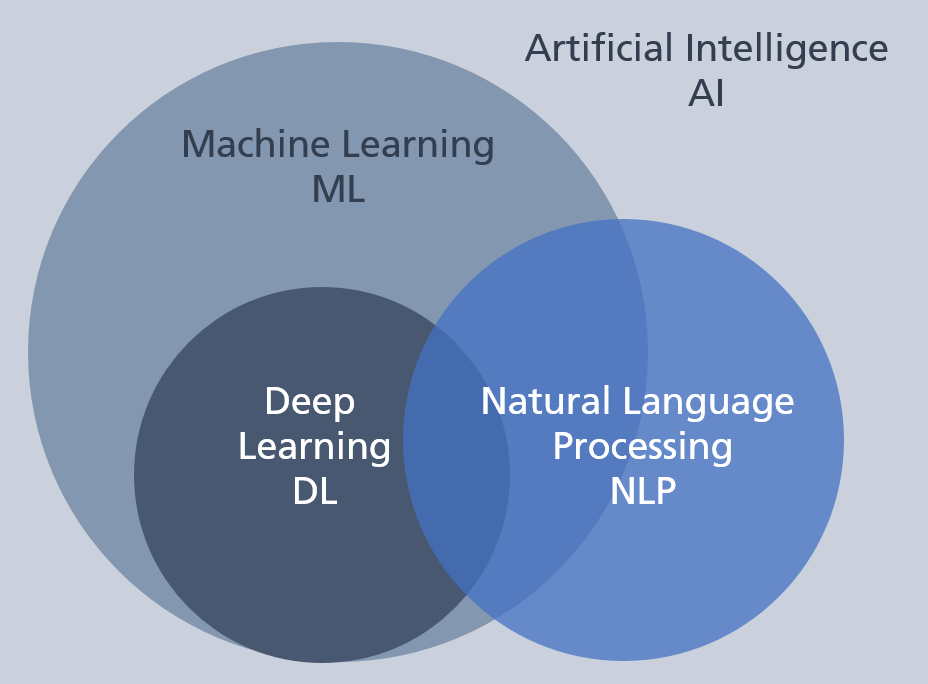
Fig. 1: The interrelationship of Artificial Intelligence, Machine Learning, Deep Learning and Natural Language Processing.
When it comes to realizing our use cases, we work in the field of Machine Learning (ML), or more precisely, in a sub-field of ML called Deep Learning (DL).
ML deals with the development of algorithms that can learn how to perform tasks autonomously by processing and understanding a large number of examples that create an extensive contextual understanding.
DL, as a sub-field of ML, is centred around the layered architecture of artificial neural networks.
Forms of Machine Learning
There are three distinct forms of machine learning:
- Supervised learning: Here a system is given a fixed set of instructions on how to react to data input. This is the most common model of machine learning and the easiest to implement. It’s used for AI functions such as facial recognition. The assessment of its output performance is called its ‘ground truth’.
- Unsupervised learning: This machine learning model automatically and autonomously finds patterns and structures in large volumes of raw input data. This model is at the centre of features such as media and product recommendations.
- Reinforcement learning: Here a system learns how to optimize its performance through the mistakes it makes. This is aimed at creating greater productivity and efficiency through repetitious data inputs.
For our three use cases, we use the most common model: supervised learning.
Training Principles in Supervised Learning
What is the learning process for a model consisting of several layers of artificial neural networks? The answer is simple. Sample data. Lots of sample data. This data is otherwise known as training data because learning in this sense means training a model on how to optimally perform the tasks required.
With our three use cases, we are constantly handling natural language text. The difficulty with natural language is that it is infinitely complex, ambiguous and unstructured. To address this, natural language training sentences must firstly be structured into a numerical representative form. The training of the model then goes roughly so:
 Fig. 2: Machine learning – the training principles
Fig. 2: Machine learning – the training principles
When it comes to training a model, what’s needed first is training data consisting of an x input and a correct corresponding (ground truth) y output. At this point, it’s only an initial model that is being trained and improved. For this, we need one more thing; a Parameter Vector w to reflect the model’s properties. At the beginning of the training, this parameter vector is chosen randomly, and is adjusted incrementally during the training process to make it better and better at performing the tasks required.
The basic steps of training are as follows:
Step 1- Make a prediction: The model predicts the output value () from the random x input and model properties in the form of the parameter vector w.
Step 2- Calculate losses: The model calculates the difference in value between the predicted output value and the expected output y. The difference is referred to as a loss.
Step 3- Optimization: The model autonomously adjusts the parameter vector to minimize losses.
After each adjustment to a parameter vector, this process is repeated until the performance can’t be improved anymore.
Technical Foundations
In contrast to the early days of AI, nowadays there is a wealth of public information for deep learning models for NLP and ready-made templates that can be implemented straight away.
In the context of our use cases, we decided that for completing the first task (structuring the natural language training sentences into a numerically represented form, known as Word-Embedding) we would use the BERT language model from Google. BERT was developed by Jacob Devlin and his collaborators at Google and published in 2018. Since then it’s been applied to Google search, among other things.
Standing for Bidirectional Encoder Representations from Transformers, BERT is essentially a so-called ‘transformer’ model. Transformer models are especially suitable for NLP tasks because they can recognize the context of input and adjust their predictions and performances accordingly. For example, in the context of musical instruments, a ‘bow’ would be recognized by a transformer model as something used with a string instrument, rather than a respectful gesture or the type used in archery.
Training a model to process natural language requires a huge amount of training data and a generous amount of time to reach an optimal level, which makes training a relevant cost factor in AI application development. These points factored into our decision to use BERT, already coming with an extensive lexicon and corresponding parameters.
The Basic Architecture
BERT is the linguistic foundation that we are building on. However, it doesn’t automatically provide for all our AI needs. This is what is still required:
- A holistic model architecture
- Use case-specific training
- Integration with features in objectiF RM and objectiF RPM
I would like to end this article with a look at the model architecture and the necessary training required:
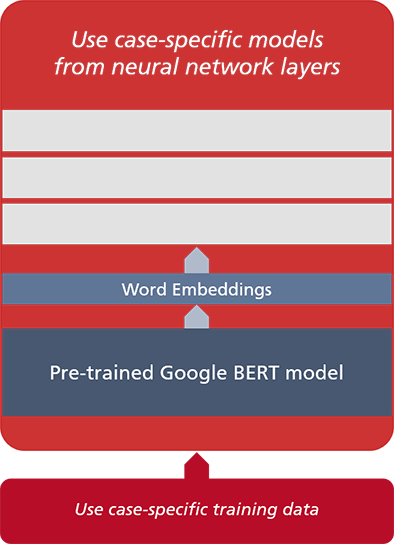
Fig. 3: Uniform model architecture for selected use cases
Each use case requires its own model consisting of layers of neural networks, each of which is trained with use case-specific data. Each use case-specific model is accompanied by a corresponding BERT model that is pre-trained with general and domain-specific vocabulary. It digitizes the training data, i.e. generates the word embeddings.
The use case-specific models are being implemented by microTOOL using the data stream orientated programming framework TensorFlow and the Official.NLP library, both of which were originally developed by Google.
In the next article in this series on AI, we’ll take a closer look at our first use case, namely the voice control feature for objectiF RPM. If you are yet to try out this tool, download a trial version here.
Sources:
Sowmya Vajjala et al.: Practical Natural Language Processing. 1st. Ed. O’Reilly Media, 2020