
“Who are you talking to?”
I gave up on asking family members this question a long time ago. I already know the standard answers: “Alexa”, “Google”, “my phone”, etc. Based on my own experience, digital voice assistants have become an integral part of our everyday lives. The statistics back this up; a survey from 2019 in Germany (see [1]) found that 60% of those asked had used a voice assistant at least once. 92% of the survey’s participants had also heard of Amazon’s Alexa, as well as 77% having heard of both Google’s voice assistant and Apple’s Siri feature. With this in mind, it’s only a matter of time before users of objectiF RPM ask: “Why is there no voice assistant feature? Why can’t I simply tell the tool to ‘open this query‘ or ‘show me the Kanban board for this organization’? Or even ‘create a requirement for this’ or ‘start a video call with such-and-such a person’?“
In anticipation of the demand for a voice assistant feature within objectiF RPM, which will simplify and hasten work processes, we have begun to develop 3 use cases for artificial intelligence, or more specifically, for Machine Learning and Natural Language Processing. The first of these 3 use cases, which I mentioned in the previous article in this blog series, is a voice control feature.
In the following sections of this blog post, I will describe, from a user perspective, how this new voice control feature works, as well as the technical intricacies that are under the hood.
Three Steps to the Result
There are three clear steps between objectiF RPM receiving vocal input data and producing the desired result.
Before any vocal data inputs can be made, however, the voice assistant feature must first be activated. With objectiF RPM, this is done by clicking on the small button with a microphone symbol.
Step 1: Speech-to-Text
In order for an audio signal of a human voice to be processed, it first needs to be converted into natural language text. For this, an Automatic Speech Recognition (ASR) processor – otherwise known as Speech-to-Text processor – is used. For our voice control feature, we are using Microsoft’s Azure Cognitive Services.
Step 2: Intent Recognition
The text that is generated from the audio signal then needs to be converted into a Numerical Representation, known otherwise as Word Embeddings. For this purpose, we employ the pre-trained Bert Encoder from Google. The processed results from word embeddings are more than text in digital form; they contain semantic and syntactic information that BERT computes from the context of the text. The word embeddings are then used to analyse the user’s intentions.
In figure 1, we take a closer look at this. An audio signal is processed into two types of word embedding: Token Embeddings for each sentence component and a Sentence Embedding, which is calculated by finding the averages of all token embeddings; this latter process of finding averages is also called Pooling and its purpose is to prioritize the actions that the user desires to take over the individual sentence components. In other words, the aim is to recognize the overall sentence context rather than just myopically assess individual words.
Identifying the need for the system to recognize user intentions is one thing, actually making it happen is another. So how can it be done? This is where a classifier comes in. A classifier is a use-case specific dimension of our AI model, or rather the neural network for NLP, and used to assign data to pre-defined classes. Here’s an example of how it works:
A user says to a voice assistant, “show me the query for use cases in the package for use cases.” This prompts the use of two classifiers, the first of which is capable of recognizing predefined classes of action, such as ‘create’ and ‘open’. We label this class the Intent Type; data input for this class is predicated on sentence embedding. This means that the system, which has been trained to recognize semantic links through a large volume of example sentences, will class sentences that contain words such as display and show in the intent type for ‘open’.
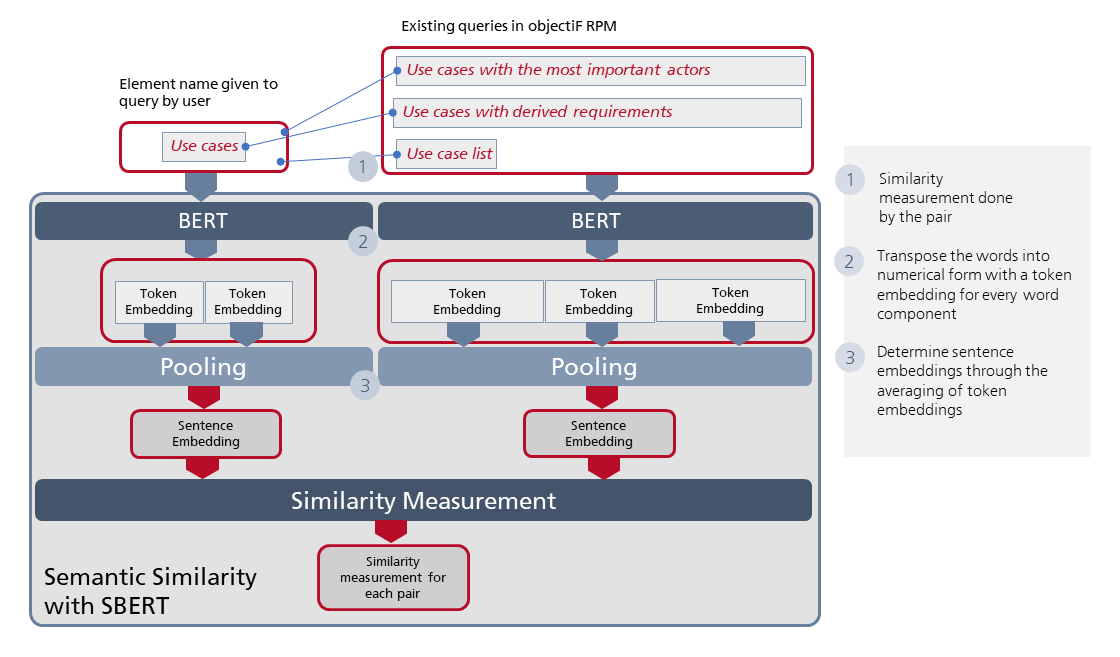
Figure 1: Intent Recognition: The AI model’s work process from receiving the voice recording to realizing the desired result of the user
In order for the system to recognize the intentions of the user, a second classifier is needed to process the token embeddings. This second classifier groups inputs by Element Type as found in objectiF RPM, such as ‘Query’, ‘Diagram’, ‘GanttChart’, KanbanBoard’, ‘Dashboard’, etc. As a result of a training process involving a large number of sample inputs, it has learnt that Query, Evaluation and Listing all belong to the same ‘Query’ element type. Each element has its own system context in objectiF RPM, meaning that they are present in a specific package or project. Accordingly, this classifier also recognizes Context Element Types such as ‘Package’ or ‘Project’.
So, what has been achieved by the end of this second step? The answer to this question can be provided by another example:
The voice assistant in objectiF RPM has received the request to find the query for use cases that is located in a package also called use cases. Sometimes we are lucky and the recorded input data is an exact match for the desired element, which means that the system is already able to realise the desired result of the user. However, in this case, there is no query for use cases. There is, however, a query called use case list, which happens to be the query that the user intended to identify to the system. In order for objectiF RPM to conclude that use case list was the actual query that the user was referring to, one final step is necessary.
Step 3: Semantic Similarity
With the help of the AI system, it must first be determined whether or not there are similar (or, ideally, matching) names that correspond to the element or context element names that the user has referenced in their vocal data input. It should be noted that in objectiF RPM, element and context element names can be made up of several words. For this purpose, we need an additional AI model that provides a numerical representation for word orders that are to be compared with each other, which can then be used to calculate the semantic similarity of the different word orders. The model we seek is the pre-trained Sentence-BERT, usually abbreviated to SBERT. This model has been developed for the precise purpose of optimising the original BERT architecture when it comes to determining semantic similarities.
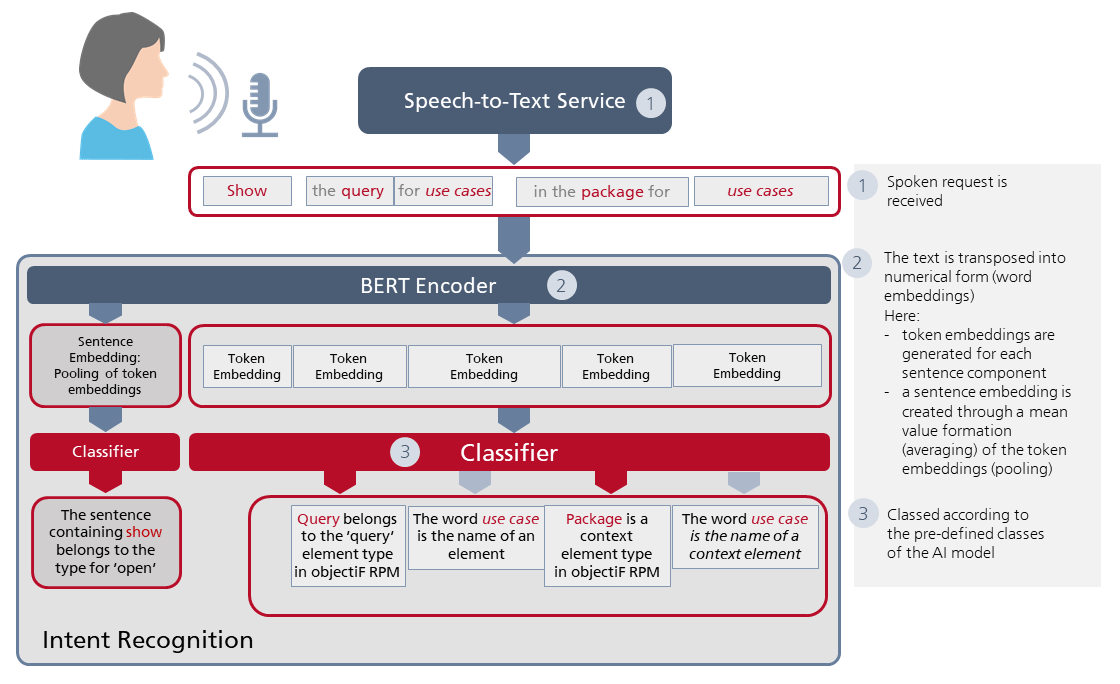
Figure 2: The dimensions of the AI model used to recognize semantic similarities between the words spoken to the voice assistant by the user and the names that are in the objectiF RPM repository
What makes SBERT (see fig. 2 above) special is that two BERT models can be employed simultaneously and parallel to each other. For our intents and purposes, one BERT model can therefore be used for the respective element or context element name, and the other for comparing these names to those in the objectiF RPM repository. Both of these BERT models provide a numerical value for each word inputted. From the token embeddings, a form of sentence embedding is processed through mean value formation (pooling). With the sentence embedding of the element or context element name referenced by the user and the individual sentence embeddings of the names from the repository, a value of their similarity is calculated. We won’t get into the mathematical intricacies behind this process. Instead, try to image a black box (referred to as the ‘Similarity Measurement’ in figure 2), which provides a measure of the similarity between the wording of the user’s vocal data input and the actual names that exist in the repository.
The Extended Architecture of objectiF RPM
The AI system described thus far also needs to be integrated into the client/server architecture of objectiF RPM. An overview of how these new AI components can be incorporated into the tool’s architecture is shown below in figure 3:
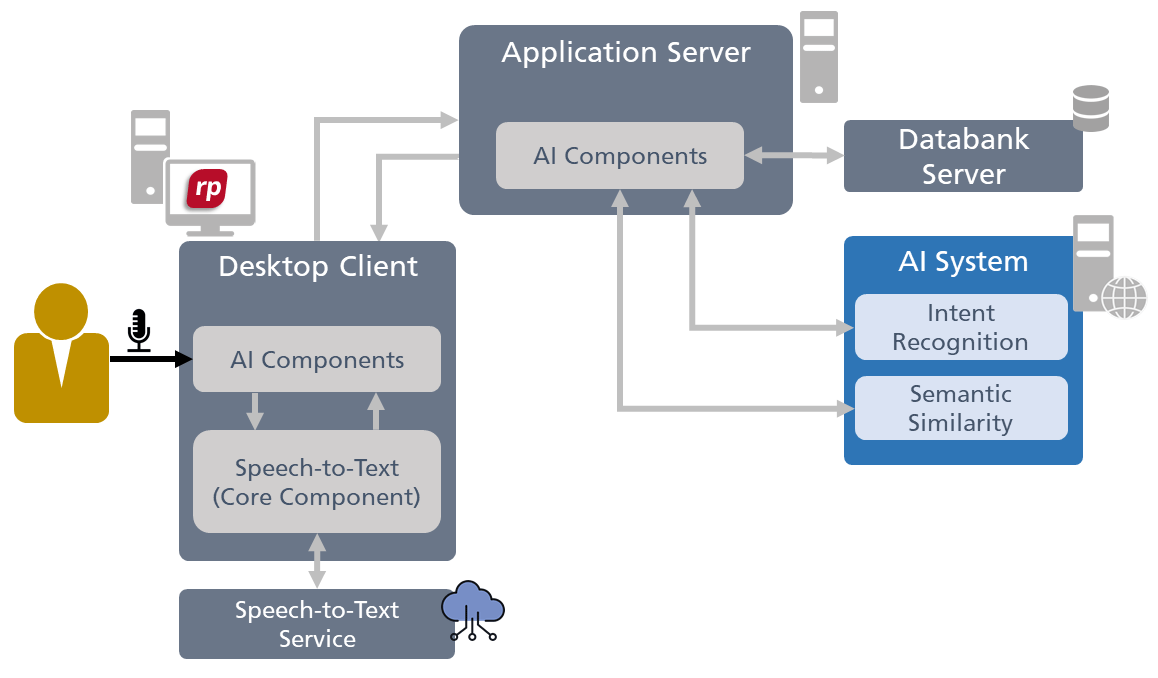
Figure 3: Here is a guide to including the components of the voice assistant into the architecture of objectiF RPM
That’s all we’ve got so far on the voice assistant feature for objectiF RPM. In the next blog entry of this series, we will take a look at the second AI use case for the tool, namely how AI can be utilized to improve the comprehensibility of requirements. If you haven’t yet tried objectiF RPM, click here to download a free trial.
Sources:
[1] https://de.statista.com/themen/4271/digitale-sprachassistenten/#dossierKeyfigures, visited on 03.02.2022